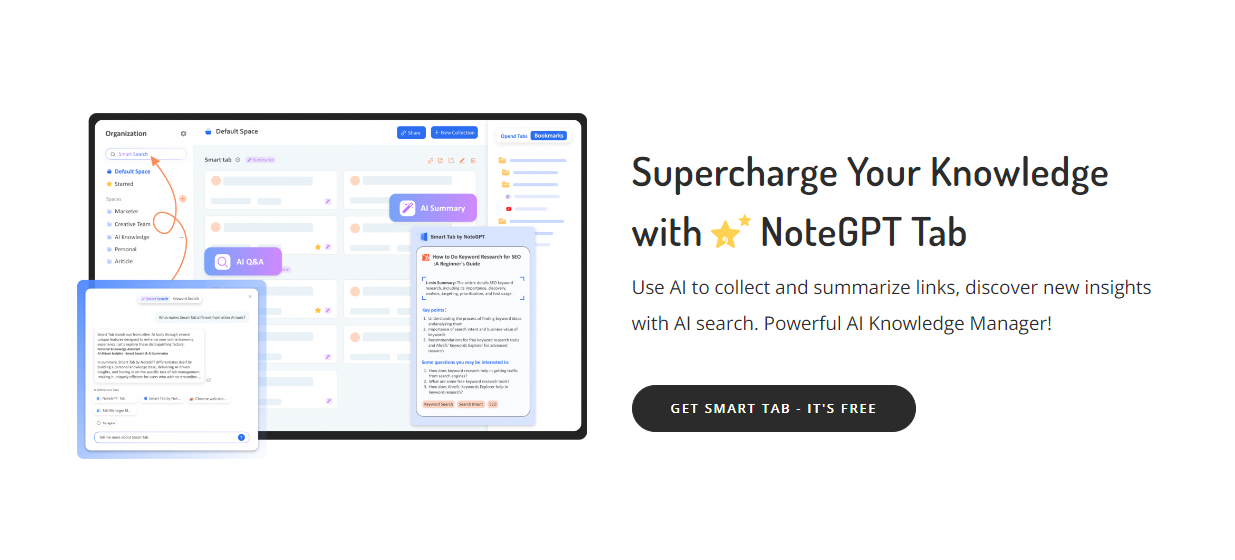
What is the significance of a specific system for annotating and organizing large datasets, particularly in the context of knowledge representation and information retrieval? A well-structured system for this purpose could prove invaluable for tasks ranging from research to practical applications.
A system for annotating and organizing large datasets, focusing on tagging, categorizing, and linking data points, could be crucial for effectively managing information. This system would likely utilize standardized methods for creating and linking these annotations. For example, it might employ ontologies or specific metadata schemas to enable consistent organization and efficient retrieval of relevant information. The system would be vital in ensuring a standardized approach to knowledge representation. Imagine a library catalog, but on a massively scaled and increasingly complex level.
Such a system offers significant benefits in various fields. Enhanced searchability, improved knowledge integration, and accelerated research are key advantages. This type of system would allow for more in-depth analysis and the identification of hidden patterns or relationships in the data. The ability to systematically link data points across disparate sources would also be crucial for many research endeavors, potentially accelerating the discovery process. The historical trend towards bigger, more intricate data sets necessitates robust approaches for handling and extracting knowledge from them.
Moving forward, the potential of such a system will be explored in the context of its applications in various fields. Specific examples of how these systems are currently being utilized will be discussed, demonstrating the practical value of robust data annotation and organization methodologies. Furthermore, limitations and future directions of such systems will also be reviewed.
notegtp
Understanding the key components of a system for annotating and organizing large datasets is crucial for effective knowledge management. A well-structured approach is vital for managing the complexity of modern information.
- Data annotation
- Knowledge representation
- Information retrieval
- Metadata schemas
- Ontology development
- Data linking
- Scalability
These key aspects form a framework for effective information management. Data annotation ensures tagged and categorized data for accurate analysis. Knowledge representation enables the organized storage and retrieval of complex information. Information retrieval mechanisms facilitate finding specific data points within the dataset. Metadata schemas provide structure and consistency. Ontology development establishes clear relationships between data items. Data linking connects data from diverse sources. Scalability is essential to manage the volume and complexity of large datasets. A well-functioning system needs to handle vast amounts of data to ensure effective analysis. For example, a system incorporating these aspects could efficiently organize and retrieve research papers, linking authors, topics, and methodologies for rapid knowledge synthesis.
1. Data Annotation
Data annotation, a crucial process in managing and extracting value from large datasets, forms a foundational element for systems like notegtp. Accurate and consistent annotation is essential for the successful application of these systems in various domains, such as knowledge representation and information retrieval. Without well-defined and comprehensive annotations, a system for handling massive datasets would lack the context and structure necessary to effectively process and utilize information.
- Data Labeling and Categorization
This facet involves the systematic labeling and categorization of data points within the system. An example includes tagging research articles with keywords reflecting subject matter, methodology, or key findings. Proper labeling allows for focused retrieval of information and facilitates grouping similar data items. This structured approach to annotation directly supports the functionality of notegtp by enabling the system to discern relationships and similarities between different data points.
- Contextual Information Enrichment
Annotation goes beyond simple labeling; it involves embedding contextual information. This might include adding timestamps, geographical locations, or relationships between different data elements. For example, in a system designed to analyze social media posts, annotation could include details about the author, date of posting, and location. Such contextual information enriches the data, allowing notegtp to understand the nuances of the data beyond simple classifications, enabling more accurate analysis and retrieval.
- Quality Control and Standardization
The consistency and accuracy of annotations significantly affect a system's ability to analyze and draw meaningful conclusions. Implementing stringent quality control measures ensures that data is labeled reliably and uniformly across the dataset. Standardized annotation schemes minimize ambiguity and allow for seamless integration of different data sources. In the context of notegtp, this facet ensures the system can interpret and process information with precision, avoiding erroneous conclusions arising from inconsistencies in labeling.
- Scalability and Efficiency
Data annotation strategies must address scalability issues when working with massive datasets. Efficient annotation techniques and tools are crucial to support the large-scale operations needed by notegtp. Automated approaches or semi-automated tools can effectively manage large volumes of data while maintaining annotation quality. Streamlining the annotation process is critical for the efficient handling of massive datasets and minimizing potential bottlenecks.
In summary, data annotation is not merely a preprocessing step but a fundamental building block for systems like notegtp. The quality, consistency, and comprehensiveness of annotations determine the effectiveness of the knowledge representation and retrieval processes. Thorough attention to each facet of data annotation is critical for creating a system that effectively handles and derives value from complex data.
2. Knowledge Representation
Knowledge representation forms a cornerstone of any system designed for efficient handling and extraction of knowledge from extensive datasets. In the context of a system like notegtp, effective knowledge representation is paramount. It dictates how information is structured, linked, and ultimately interpreted within the system. A well-defined representation method allows the system to understand relationships between concepts, identify patterns, and support advanced queries and analysis. Failure to establish a sound knowledge representation model can lead to a system that struggles with complex queries, lacks the ability to integrate information from disparate sources, and ultimately underperforms in knowledge discovery.
The choice of representationwhether using ontologies, semantic networks, or other formalismsdirectly impacts the system's capacity for handling intricate relationships between data points. For instance, representing research papers not just by keywords, but also by their authors, citations, and related fields establishes a more robust knowledge graph. This allows the system to not only find papers on a specific topic but also identify related research streams, influential authors, and potential gaps in knowledge. A practical example might involve a system for scholarly literature analysis. By using ontologies to represent concepts within the field, the system can identify papers that discuss related ideas, enabling researchers to easily grasp existing knowledge and identify unexplored avenues of research. In essence, well-structured knowledge representation enables the identification of subtle connections, a cornerstone for advanced analysis and insights.
The significance of a robust knowledge representation system for notegtp is evident. A well-defined model ensures consistency in data interpretation and facilitates complex queries and analysis. This, in turn, improves the system's overall performance in extracting, organizing, and utilizing knowledge from the dataset. Challenges in this area include maintaining the consistency and accuracy of knowledge representation as the dataset grows and evolves. Furthermore, the effective linking and interoperability of diverse data sources is paramount to ensure a complete and comprehensive knowledge representation. The continued development of advanced knowledge representation techniques remains crucial for the advancement of systems like notegtp.
3. Information Retrieval
Information retrieval (IR) is a crucial component of systems like notegtp. Effective IR mechanisms are essential for accessing and utilizing information within large datasets. The connection is direct: notegtp requires sophisticated IR capabilities to efficiently locate and retrieve specific information from the vast collection of data it manages. Accurate and rapid retrieval is fundamental to the utility of such a system. Imagine a research library possessing millions of documents; a well-designed IR system is vital for enabling researchers to find relevant materials quickly and effectively.
The practical significance of this connection is evident in various applications. In academic research, a robust IR system within notegtp can identify pertinent articles, datasets, and other resources, potentially accelerating the research process. In business intelligence, this capability enables analysts to locate market trends, customer preferences, and other critical data points. Similarly, in healthcare, efficient retrieval systems could enable doctors to access patient records and relevant medical literature swiftly. The ability to filter and refine searches within a system like notegtp, based on complex criteria, is essential for obtaining valuable insights. For instance, a scientist might need to find all articles on a particular topic published in the last five years, referencing a specific methodology. A well-designed IR system would efficiently locate these resources.
In conclusion, the relationship between information retrieval and systems like notegtp is fundamental. A robust IR component is critical for efficient data access and utilization within large datasets. The success of notegtp, and similar systems, heavily relies on the effectiveness of its information retrieval mechanisms. Challenges include the scalability of IR systems to accommodate ever-increasing data volumes and the need for advanced techniques to handle complex queries across multiple data sources. Further development in this area is critical to meeting the increasing demand for efficient information retrieval within vast datasets.
4. Metadata Schemas
Metadata schemas play a critical role in systems designed for managing and retrieving information from extensive datasets, including systems analogous to notegtp. These schemas provide a structured framework for describing data, enabling consistent organization, efficient retrieval, and meaningful analysis. A well-defined metadata schema acts as a blueprint, outlining the types of information to be recorded and how these details should be formatted. This structure is crucial for enabling effective querying, filtering, and analysis within the system, maximizing the potential value derived from the underlying data.
The importance of metadata schemas is evident in various real-world applications. Consider a library cataloging system. Metadata schemas dictate how books are describedauthor, title, publication date, genre, and other relevant information. This structured approach facilitates searching, organization, and retrieval of books. In a similar vein, a system for managing scientific research papers would leverage a metadata schema to capture details like authors, keywords, research areas, and publication venues. This structured approach allows researchers to quickly locate relevant papers based on specific criteria and facilitates analysis across the corpus of research. The benefits extend to other domains like e-commerce, where product metadata enables efficient search and filtering based on attributes like price, color, or size. In each case, the schema establishes a common language for describing data, enabling effective information retrieval and management. This standardized representation is essential for the smooth operation of a system like notegtp, ensuring consistent handling of data elements and enabling sophisticated querying.
In essence, metadata schemas are fundamental to systems for information management. They establish a standardized way of describing and organizing data. This standardization is critical for the efficient retrieval and analysis of information within large datasets, directly impacting the performance and usefulness of systems like notegtp. Challenges in implementing effective metadata schemas include defining appropriate descriptors, ensuring data consistency, and maintaining schema evolution to reflect evolving data needs. Understanding and addressing these challenges is essential for developing robust information management systems that maximize the value extracted from large datasets.
5. Ontology Development
Ontology development plays a critical role in systems designed for managing and extracting knowledge from extensive datasets, including systems analogous to notegtp. An ontology, in this context, provides a structured representation of concepts and their relationships within the domain of interest. This structured approach is crucial for notegtp's ability to interpret, integrate, and retrieve information effectively. A well-defined ontology establishes a common understanding of the concepts represented in the data, facilitating accurate interpretation and enabling the system to identify meaningful connections and relationships between different data points.
The importance of ontology development as a component of notegtp is evident in its capacity for knowledge representation. Ontologies define the vocabulary used within the system, establishing clear relationships between entities and concepts. This structure allows notegtp to move beyond simple keyword matching, enabling deeper semantic understanding of the data. For instance, in a system for scientific literature analysis, an ontology might define concepts like "enzyme," "reaction," and "mechanism." This structured definition allows the system to link documents discussing similar mechanisms, regardless of the specific terminology used by different authors. This enhanced ability to identify semantic relationships across diverse sources is a key benefit for a system like notegtp.
Effectively employing ontology development enables a more sophisticated approach to information retrieval. By linking data elements according to an explicitly defined ontology, the system can answer queries that are more complex and nuanced. For example, researchers might be interested in documents describing enzyme-catalyzed reactions within specific cellular contexts. An ontology explicitly defining relationships between enzymes, reactions, and cellular locations provides the foundation for this more targeted and insightful query. In summary, ontology development empowers a system like notegtp to navigate the complexity of knowledge representation and retrieval, driving better insights and more profound understanding from the data.
6. Data Linking
Data linking, a crucial aspect of knowledge management, is intrinsically connected to systems like notegtp. The ability to connect seemingly disparate data points within a large dataset is essential for deriving meaningful insights. This interconnectivity allows for more comprehensive analysis, revealing hidden patterns and relationships that might otherwise remain obscured. In the context of notegtp, data linking enables the system to integrate information from various sources, enriching its understanding of the data and enhancing its functionality.
- Establishing Relationships
Data linking facilitates the establishment of relationships between different data elements. For example, linking research papers with their cited sources allows a system to understand the context of a particular study and trace the progression of ideas. In the context of notegtp, this might mean linking research articles with authors, institutions, and funding sources. This integration deepens the understanding of the information by revealing connections and dependencies between elements.
- Enhancing Data Context
By connecting related data points, data linking significantly improves the context within which individual data elements exist. Consider linking social media posts to relevant news articles. This context addition, in a system like notegtp, allows for a richer understanding of events and trends. The system can discern the correlation between online discussions and real-world events, uncovering insights not apparent from analyzing individual data points in isolation. This enriched context is critical for deriving meaningful conclusions.
- Improving Analysis and Insights
Effective data linking empowers more thorough analysis and the identification of previously hidden trends. Connecting sales figures with marketing campaigns, for instance, reveals the effectiveness of specific strategies. A system like notegtp can similarly identify patterns in research data, linking specific research methods to corresponding outcomes, highlighting effective approaches and identifying potential limitations. This connection enhances insights and ultimately improves decision-making.
- Facilitating Integration of Heterogeneous Data
Data often exists in diverse formats and sources. Data linking bridges these differences, allowing disparate data types to be integrated and analyzed together. For example, linking financial data with social media sentiment enables a deeper understanding of market reactions. Similarly, in a system like notegtp, linking scientific publications with funding records can illuminate the interplay between research interests and financial support. This integration expands the potential of the system to derive multifaceted insights.
Data linking is an essential component of a comprehensive knowledge management system like notegtp. The ability to connect and contextualize data from various sources significantly enhances the system's capabilities for analysis, knowledge extraction, and informed decision-making. Robust data linking methods and technologies are essential for the effective functioning of such systems in today's increasingly interconnected world.
7. Scalability
Scalability is a critical attribute for systems like notegtp. The ability to accommodate increasing volumes of data and user demands without significant performance degradation is paramount. As data sets grow in size and complexity, a system must adapt to maintain efficiency and relevance. The fundamental requirement for scalability ensures the system's continued viability and value proposition as the underlying data expands.
The importance of scalability in notegtp is reflected in real-world scenarios. Consider a system for scientific literature analysis. As the number of published papers increases exponentially, the system must remain functional and capable of handling and analyzing these new data points. Similarly, a system tracking financial transactions needs to adapt to the continuous influx of data. A lack of scalability would result in a system that rapidly becomes overwhelmed, slowing retrieval times, degrading functionality, and eventually rendering it practically unusable. Scalability allows the system to maintain its core functions and value proposition as data volume and complexity increase.
Understanding the connection between scalability and systems like notegtp is crucial for effective design and implementation. A poorly designed system lacking scalability will not be able to accommodate future growth, thus limiting its long-term utility. Careful consideration of scalability principles during the system's conception and development is critical to ensure sustained performance and relevance in a dynamic environment. This understanding demands proactive measures, such as modular design, adaptable architecture, and robust database systems. Failure to address scalability necessitates periodic system overhauls, adding substantial cost and disrupting operations. A scalable system, therefore, is an investment in the system's future, supporting long-term utility and effectiveness, and ensuring that it remains a valuable asset for users and stakeholders.
Frequently Asked Questions (notegtp)
This section addresses common inquiries regarding notegtp, a system for annotating and organizing large datasets. Clear and concise answers are provided to clarify key aspects of the system.
Question 1: What is the primary function of notegtp?
notegtp serves as a comprehensive platform for annotating and organizing large datasets. Core functionality involves tagging, categorizing, and linking data points to facilitate efficient information retrieval and knowledge extraction. Key aims include enhancing searchability, streamlining knowledge integration, and accelerating research processes.
Question 2: What types of data can notegtp handle?
notegtp can process a wide range of structured and unstructured data. This includes, but is not limited to, research papers, social media posts, scientific literature, financial records, and other forms of textual, numerical, or multimedia data.
Question 3: How does notegtp enhance knowledge representation?
notegtp employs advanced methods for knowledge representation, including standardized ontologies and metadata schemas. This structured approach facilitates the organization of data elements, improving connections between concepts and enabling complex queries. This structured approach to knowledge representation is vital for nuanced analysis and insights.
Question 4: What are the benefits of using notegtp for research?
Using notegtp for research offers several advantages. Enhanced searchability allows researchers to quickly locate relevant information. Improved knowledge integration connects related research streams, accelerating knowledge synthesis and discovery. Increased analysis depth assists researchers in identifying trends and patterns within vast datasets.
Question 5: What are the technical limitations of notegtp?
While notegtp offers significant advantages, limitations exist. The scalability of the system is crucial, as massive datasets can present challenges. Data quality and consistency are also important factors, with inaccurate or inconsistent data potentially hindering the system's effectiveness. Overcoming these limitations often involves careful data preprocessing and the use of robust annotation strategies.
In summary, notegtp offers a powerful platform for handling and extracting knowledge from large datasets, providing researchers and analysts with valuable tools for information retrieval and analysis. Understanding the system's capabilities and limitations is crucial for optimal application and maximizing its benefits.
The following sections delve deeper into the specific functionalities and implementation details of notegtp.
Conclusion
This exploration of notegtp, a system for annotating and organizing large datasets, has underscored the critical role of such platforms in contemporary knowledge management. Key aspects, including data annotation, knowledge representation, information retrieval, metadata schemas, and ontology development, were examined, highlighting their interdependence and mutual influence on system effectiveness. Scalability and the ability to handle increasing data volumes were identified as crucial factors for long-term viability. The analysis revealed that the quality and consistency of annotation, coupled with a robust knowledge representation framework, are foundational for successful information retrieval. Data linking, connecting seemingly disparate data points, significantly enhances analysis capabilities and provides a broader understanding of complex datasets. The discussion further emphasized the importance of a well-defined metadata schema and the strategic development of ontologies to ensure consistent data interpretation and effective querying. The challenges associated with large-scale data management, such as maintaining data quality, handling increasing data volumes, and adapting to evolving data needs, were also acknowledged.
In conclusion, notegtp, and similar systems, represent a critical advancement in knowledge management. Their ability to extract, organize, and synthesize knowledge from vast datasets has significant implications across numerous fields, including research, business intelligence, and healthcare. The ongoing development of such systems must remain focused on addressing the challenges of scalability, data quality, and evolving data needs. Future research should explore the potential of these systems to further enhance the utilization of knowledge within large-scale data environments. Continuous innovation and adaptation in this domain are essential to meet the demands of a world increasingly reliant on data-driven insights.
You Might Also Like
Watch Yoo Jung-ii Full Movie - Now Streaming!Latest Tropical Storm Kirk Models & Forecasts
Is Taraji P. Henson Dating Someone? Latest 2024 Updates
Kim Kardashian Address - Find Out Here!
Lisa Left Eye Lopes: Remembering A Music Icon
Article Recommendations
- Bill Emerson Bridge History Facts
- George Sakellaris Inspiring Stories Insights
- Michael Marchetti Top Insights Strategies